
Innovation and Effectiveness in Cyber Security
Insights on Gathering Information about Websites related to Lebanon
Novel business strategies require the presence of companies and institutions online to increase the revenue or to ease the transactions. Such strategies allow for enterprises in public and private sectors not only to introduce their products or services, but also to get in contact with customers. In particular, companies are taking advantage of launching their own websites and social media profiles. Often, these websites comply with the latest design and usability best practices, whereas the security guidelines are still overlooked. A website that is insecure can lead to serious problems such as customers data exfiltration, sensitive information manipulation, phishing and being subject to hacking in general.
This blog addresses the gathering of websites' domain names and emails related to Lebanon as a first steps towards finding vulnerabilities on large scale.
Gathering domain names and emails: Collecting domain names and emails is a very crucial step in a large scale vulnerability detection process. In principle, two trivial, but important facts hold:
- the more websites are covered during vulnerabilities scanning, the more secure the overall online affair will be, and
- the more valid website‘ s emails can be found, the more the website owners can be reached and thus notified about threatening vulnerabilities in their systems.
In order to ensure a broad coverage of domain names and emails, Lebanon CERT gathered as many domain names and emails as possible from publicly, free available companies databases in Lebanon. Among all, three leading databases were selected: Lebanon-industry, 5index and yellleb databases. More details about each database will be covered in a later blogs.
Tools used for gathering domain names and emails: The collection of domain names and emails was done automatically using the programming language Python (3.7.3) and the framework Scrapy (1.6.0). Scrapy allows to crawl and scrape websites. This can be done by assigning so called ‘spiders’ to collect specific informations from the html tags, e.g., using Xpath, and then saving them in a structured form, e.g., json-format. For this project, domain names, emails, phone numbers and sectors to which the company belongs were collected by multiple spiders.
Code snippet: The following example serves as a short demonstration on how the above mentioned databases are crawled. For the sake of simplicity, code snippets of only one database will be shown, namely, Lebanon-industry.
In order to crawl https://www.lebanon-industry.com/home, a class Item() and a class Spider are implemented. The class Item() defines the fields that must be crawled from a website. It is responsible for yielding the results in a structured way:

The class Spider must override some functions:
- start_requests(): sends a request to the URL of the sector:
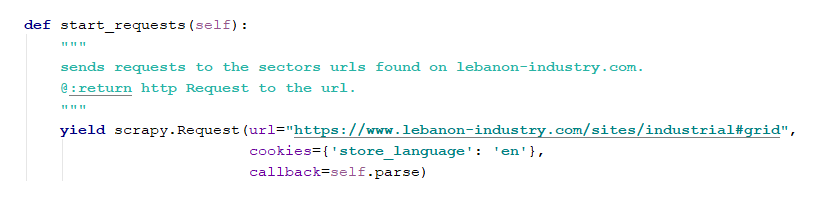
After sending the request, Scrapy receives the response. The response is the html code of the URL. Now, this html code will be parsed by a Selector(). To parse the response, the class Spider must override a second function:
- parse(): In this method, the Selector() and the Item() class must be firstly initialized.
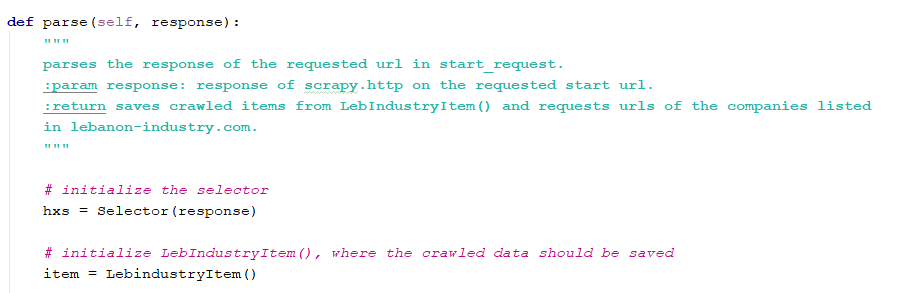
After that, the spider will be assigned to get some informations from the html tags and to save them in the Item(). To do this, a knowledge of the architecture of the database is required. In lebanon-industry database, the name of a company can be found under . The spider agent will use Xpath to extract the name in the following way:

The other fields are extracted from the website in the same way. At the end, the output will be a json file containing all relevant informations.
Results: End results is a combination of all three sources merged together to form a useful database asset. Note that this is just one method to gather domain names and emails. We use various other comprehensive methods to gather such information. We will elaborate on these other methods in later blogs.